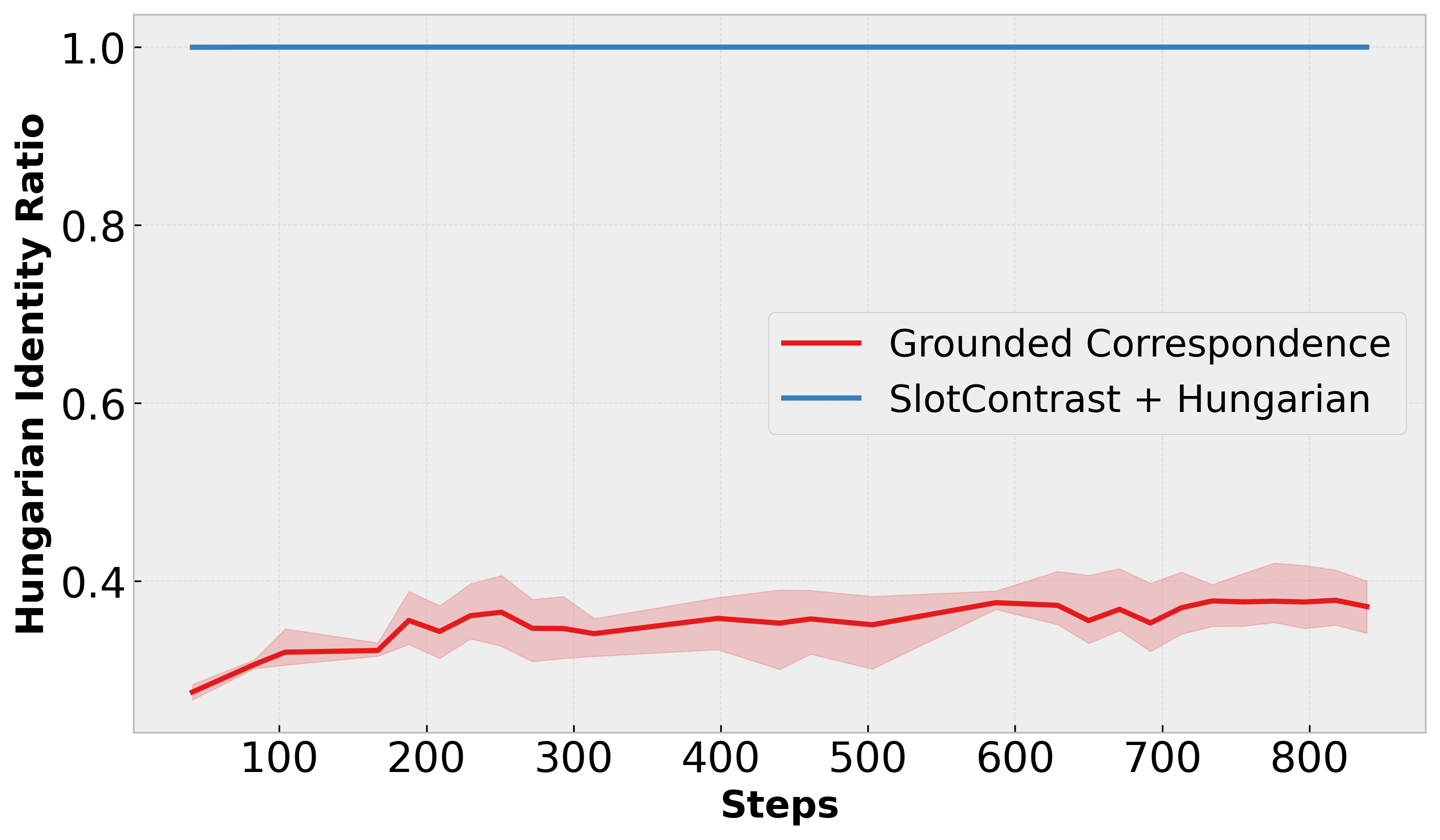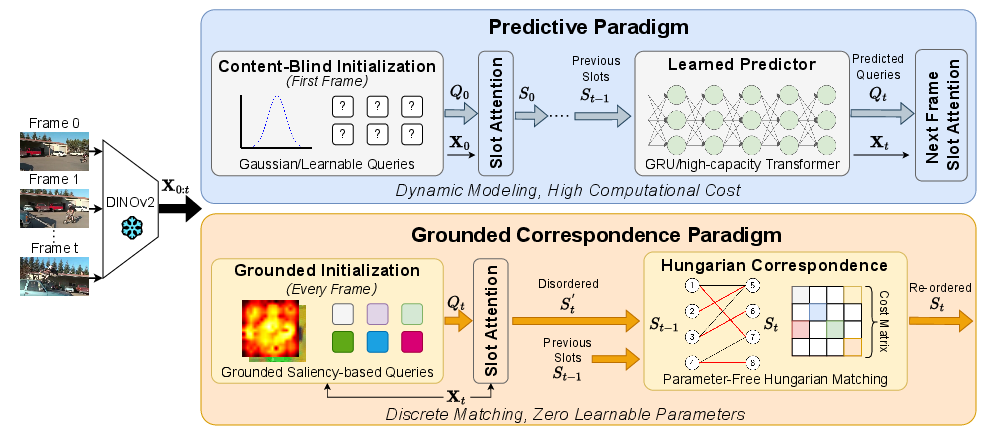
The de facto approach in video object-centric learning maintains temporal consistency through learned dynamics modules that predict future object representations, called slots. We demonstrate that these predictors function as expensive approximations of discrete correspondence problems. Modern self-supervised vision backbones already encode instance-discriminative features that distinguish objects reliably. Exploiting these features eliminates the need for learned temporal prediction. We introduce Grounded Correspondence, a framework that replaces learned transition functions with deterministic bipartite matching. Slots initialize from salient regions in frozen backbone features. Frame-to-frame identity is maintained through Hungarian matching on slot representations. The approach requires zero learnable parameters for temporal modeling yet achieves competitive performance on MOVi-D, MOVi-E, and YouTube-VIS.